Мне захотелось проверить и резюмировать то, как же можно схлопнуть тонкий диск.
Сначала резюме:
После
стандартных действий по обнулению выделенных, а затем освобожденных блоков, следует выполнить миграцию "схопываемого" диска с выполнением одного из следующих условий:
- миграция должна происходить между хранилищами на разных системах хранения.
SAN -> NAS
SAN -> локальные диски
один SAN сторадж -> другой SAN сторадж;
- миграция должна происходить пусть внутри одной системы хранения, но у VMFS хранилищ должны быть блоки разного размера;
- миграция может происходить внутри одной СХД, между хранилищами с одинаковыми блоками - но с изменением кое-какой глубинной настройки. Только для ESXi.
А теперь подробности.
С недавно полученных гонораров за книгу я прикупил аж двухтеррабайтный диск в свою тестовую лабораторию, и ставши куда менее ограниченным в дисковом пространстве, решил поиграться со "схопыванием" тонкого диска, о нюансах которого был большой пост недавеча -
thin shrink, VMFS blocksize.
Организация теста
Я создал 3 LUN на iSCSI СХД,
на двух из них VMFS с блоком = 8 МБ,
и на одном с блоком = 4 МБ.
Плюс к тому, добавил локальный диск с блоком размером 8 МБ на один из хостов.
И еще создал NFS-хранилище.
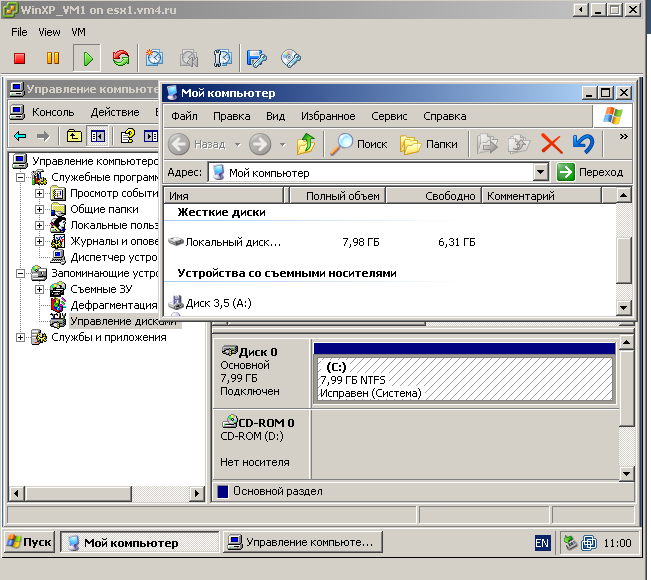
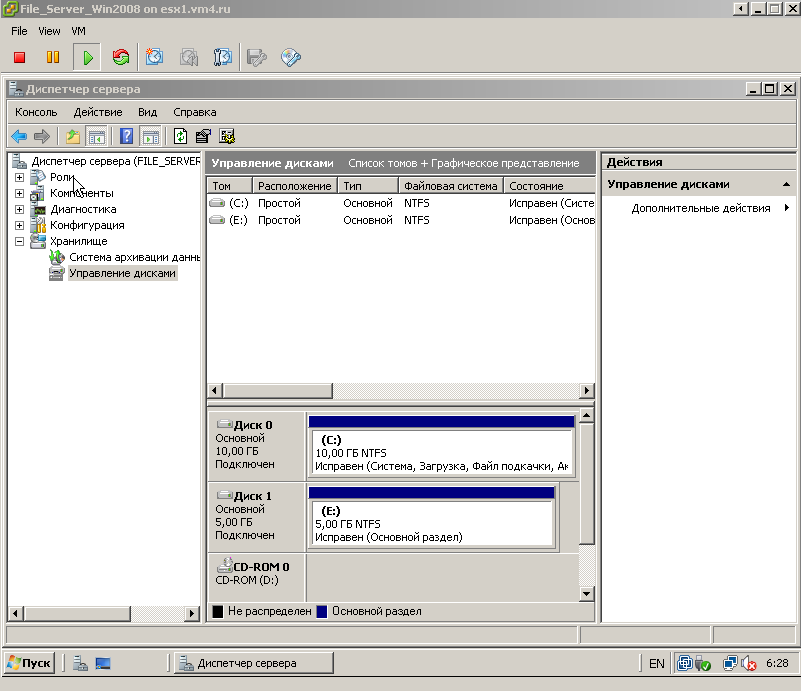
Развернул из шаблона виртуальную машину, с тонким диском, на хранилище с блоком в 8МБ. Диск тонкий, данных мало (рис.1).
 |
| Рис.1. тестовая ВМ, занимает мало места на хранилище с блоком 8 МБ |
Следующий шаг - имитация разрастания тонкого диска и повода к схлопыванию. Копирую на диск ВМ данные объемом около 3 Гб, затем удаляю их (рис.2).
 |
| Рис.2. Добавление данных на диск ВМ, затем удаление |
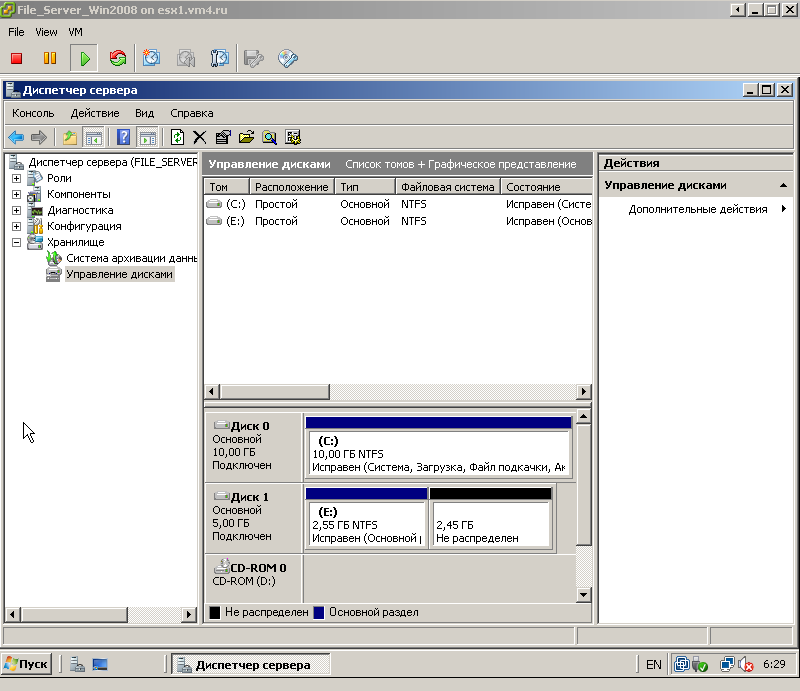
Очевидно, тонкий диск увеличивается, и не уменьшается(рис.3).
 |
| Рис.3. Тонкий диск увеличился |
Загружаем
sdelete, применяем его внутри этой ВМ:
C:\>sdelete -c c:\
SDelete - Secure Delete v1.51
Copyright (C) 1999-2005 Mark Russinovich
Sysinternals - www.sysinternals.com
SDelete is set for 1 pass.
Free space cleaned on c:\
C:\>
|
И теперь необходимо выполнить Storage vMotion (ну или миграцию выключенной ВМ) для того, чтобы диск ВМ уменьшился.
Тестирование
Сама суть моего тестирования - проверить, а куда и откуда нужно мигрировать ВМ для того, чтобы SVmotion схлопнул ее тонкий диск.
Сейчас ВМ использует хранилище с iSCSI SAN, блок 8 МБ.
Тесты я планирую такие
1) Между LUN одной схд, один размер блока. SAN 8 MB -> SAN 8 MB
2) Между LUN одной схд, разный размер блока. SAN 8 MB -> SAN 4 MB
3) Между LUN схд и локальным хранилищем, один размер блока. SAN 8 MB -> local 8 MB
4) Между LUN схд и NFS-хранилищем. SAN 8 MB -> NFS
5) Между LUN одной схд, один размер блока. SAN 8 MB -> SAN 8 MB, но попробовать через глубинную опцию принудительно использовать старый механизм копирования, схопывающий тонкие диски.
Для того чтобы слегка упростить себе задачу - я клонировал на исходном хранилище подготовленную к "схлопыванию" ВМ.
Итак, поехали.
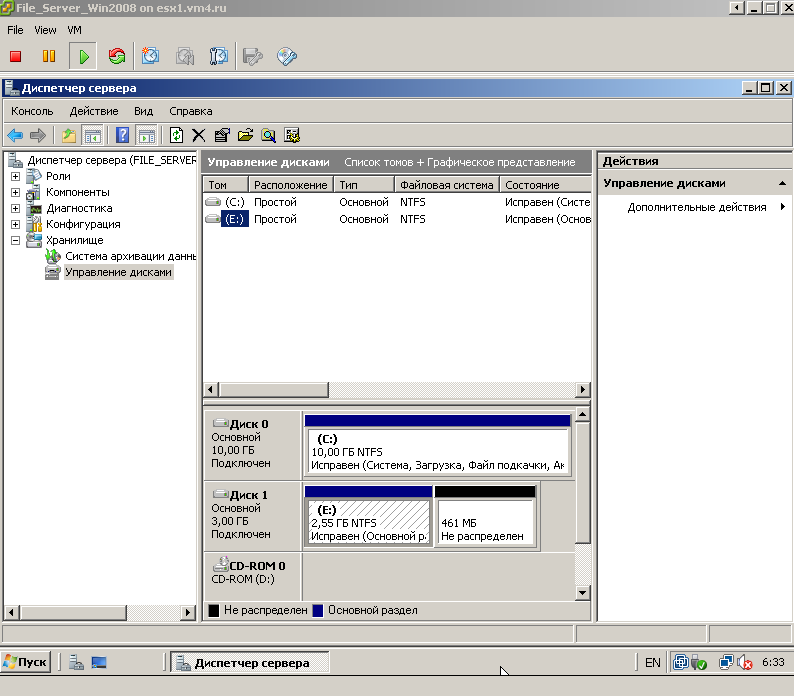
1) миграция - внутри СХД, блоки на хранилищах одного размера. Схлопывания не произошло (рис.4).
 |
| Рис.4. Тест 1 |
2) миграция внутри СХД, блоки на хранилищах разного размера. Тонкий диск схлопнулся (рис.5).
 |
| Рис.5. Тест 2 |
3) миграция между СХД (между СХД и локальным диском), блок одного размера. Диск схлопнулся (рис. 6).
 |
| Рис.6. Тест 3 |
4) миграция с VMFS хранилища на NFS хранилище. Схлопывание произошло(рис.7).
 |
| Рис.7. Тест 4 |
5) Наконец, повторяем первый тест, но сначала зайдем на ESXi по ssh и выполним следующие команды:
~ # vsish
/> set /config/VMFS3/intOpts/EnableDataMovement 0
|
Эта настройка предписывает использовать только старый механизм перемещения данных - который решает нашу задачу.
Теперь запускаем миграцию между хранилищами внутри одной СХД, с одинаковым размером блока. Схлопывание произошло(!) (рис. 8).
 |
| Рис.8. Тест 5 |
Потом только стоит не забыть вернуть в ssh и восстановить значение ранее измененной настройки:
~ # vsish
/> set /config/VMFS3/intOpts/EnableDataMovement 1
|
Комментарии
Обратите внимание на связанный момент:
во всех случаях, кроме первого, использовался менее производительный механизм для миграции данных. Напомню картинку из исходных постов:
Вот если задействуется механизм, показанный красной линией, старый - он схлопывает тонкие диски.
А два более новых механизма - не схлопывают, зато работают быстрее.
Вот интересная страница коммьюнити VMware -
Blocksize matters!
А там таблица:
Миграция между LUN одного стораджа, с задействованием нового и старого механизмов.
Разница в 4-5 раз. И это даже без VAAI.
Мораль - для скорости лучше, чтобы использовались новые механизмы.
Для "схлопывание" тонких дисков - обязательно нужно старый.
А для того, чтобы обычно использовались новые механизмы -
блоки VMFS на всех наших хранилищах должны быть одного размера.
И лучше, чтобы этот размер был бы 8 мегабайт - причин не делать так нет, а такой размер блока применим всегда.